One of my (forever) ongoing projects is to map taxon names in TreeBASE to names in external databases (such as
uBio) as a way of checking that the names are correct, adding the ability to handle synonyms, and hierarchical queries (see
my earlier post for more details).
Now, many names in TreeBASE aren't in any of the major name databases (fossils seem particularly poorly supported), which means hunting on Google for the name. In some cases I come across the name and the original reference for the name, which means I can document that the name is correct. For example, TreeBASE taxon
T8737 is
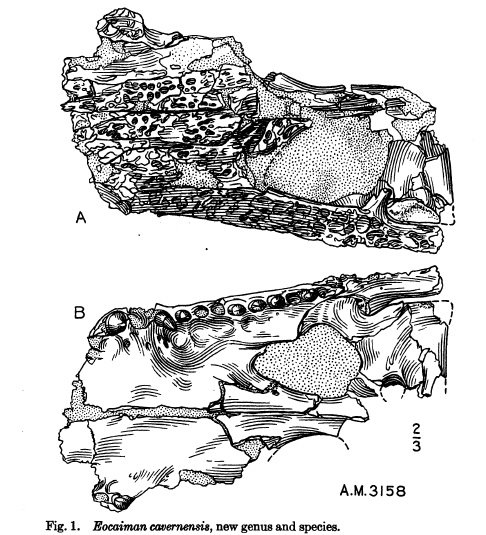
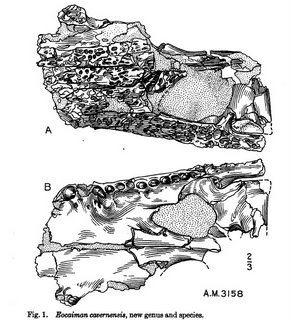
Eocaiman cavernensis, which doesn't occur in any of the name sources I use (uBio, ITIS, NCBI, IPNI, etc.). It's a fossil crocodilian, described by George Gaylord Simpson in 1933.

The original description in
American Museum Novitates is online (
hdl:2246/2050), courtesy of the AMNH's DSpace server. So, how do I link the name and the publication -- without me creating a new database to do this? Well,
Connotea to the rescue. I add
Simpson's paper to Connotea, tagged with the TreeBASE TaxonID
T8737, and
viola, the information is stored.
Now, to make use of this we need to do a little bit more, such as have a triple store that contains both the TreeBASE names and the Connotea record, but given that Connotea serves
RSS 1.0 (i.e., RDF), this is easy.
What I like about this is:
- I don't have to do much work
- The publication information is stored where others can see it and make use of it (i.e., if my experiments with these ideas fall by the wayside, the data still remain).
Now, back to the tedious task of mapping...