OK, first of all, I want one, I want one real bad.
There's been a general sense of disappointment about the iPad, which I suspect is only natural given the enormous hype leading up to the announcement, as well as the fact that the applications shown were fairly conventional. Personally I don't think book reading is where the action is. For time-sensitive stuff like newspapers, and rich, complex documents such as scientific papers, sure, but physical books strike me as a piece of technology that we're not really going to improve on, rather like knives and forks.
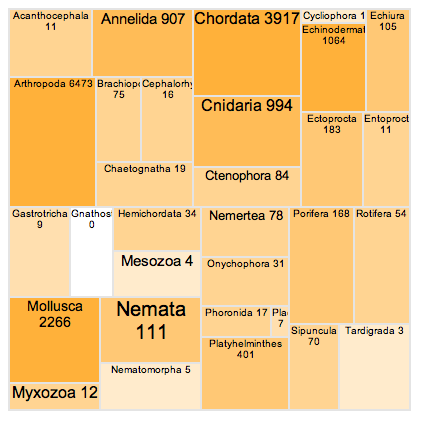
But some grasp that this is magic. What I hope the iPad will do is finally move some visualisation tools into the main stream (as much as phylogenetics can be thought of as mainstream). The challenge of visualising large phylogenies has yielded some cool tools which, sadly, remained under-developed, such as TreeJuxtaposer, which seems clunky and counter-intuituve when using a mouse, but with a touch screen would just be awesome.
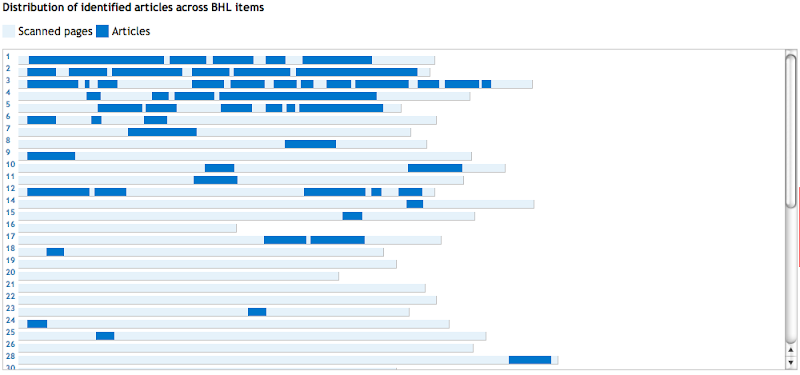
Tools such as Paloverde would also be more intuitive to use, as would the magnifier feature in Dendroscope. Imagine "pinch and zoom" in TreeJuxtaposer or Dendroscope, or for viewing large a sequence alignments.
Then there's the existing tabletop tools that I blogged about earlier:
And of course there's Perceptive Pixel's view of a taxonomic classification:
There would be some work involved porting these tools to the iPad (e.g., porting code from Java to Objective C in the case of TreeJuxtaposer and Dendroscope), but the person who does this is going to have an impact on this field comparable to Maddison brothers when they released MacClade in 1986.